How Does Footprint Analytics Make Sense?
Footprint Analytics is a blockchain analytics tool that allows users to gather, structure, and visualize data from multiple different blockchain chains. In this module, you'll understand what's the advantage of selecting Footprint as your data analystics tool.
The open data of the blockchain isn’t worth anything unless people can access and understand it. Those new to crypto tend to look at token prices exclusively, which is easy enough. However, as people gain experience in blockchain, they realize that to truly understand the market, one needs to pool-level data for DeFi, retention data for GameFi, and more—think about TVL, wallet info and deposits/withdrawals.
What if you want to investigate whale movements between different projects? Or get the full picture of a PR crisis’ impact on a protocol? How does one get this kind of data, and how can they create custom solutions to answer highly-specific questions?
Getting this raw, unfiltered data from a single chain is not that technically difficult. That’s why there are dozens of services out there in the blockchain analytics space. The process essentially entails structuring the data—standardizing the millions of lines of data being fed into a database, especially with such heterogeneous technical implementation of blockchains. With some crafty UX programming, it is converted into a visually comprehensible form.
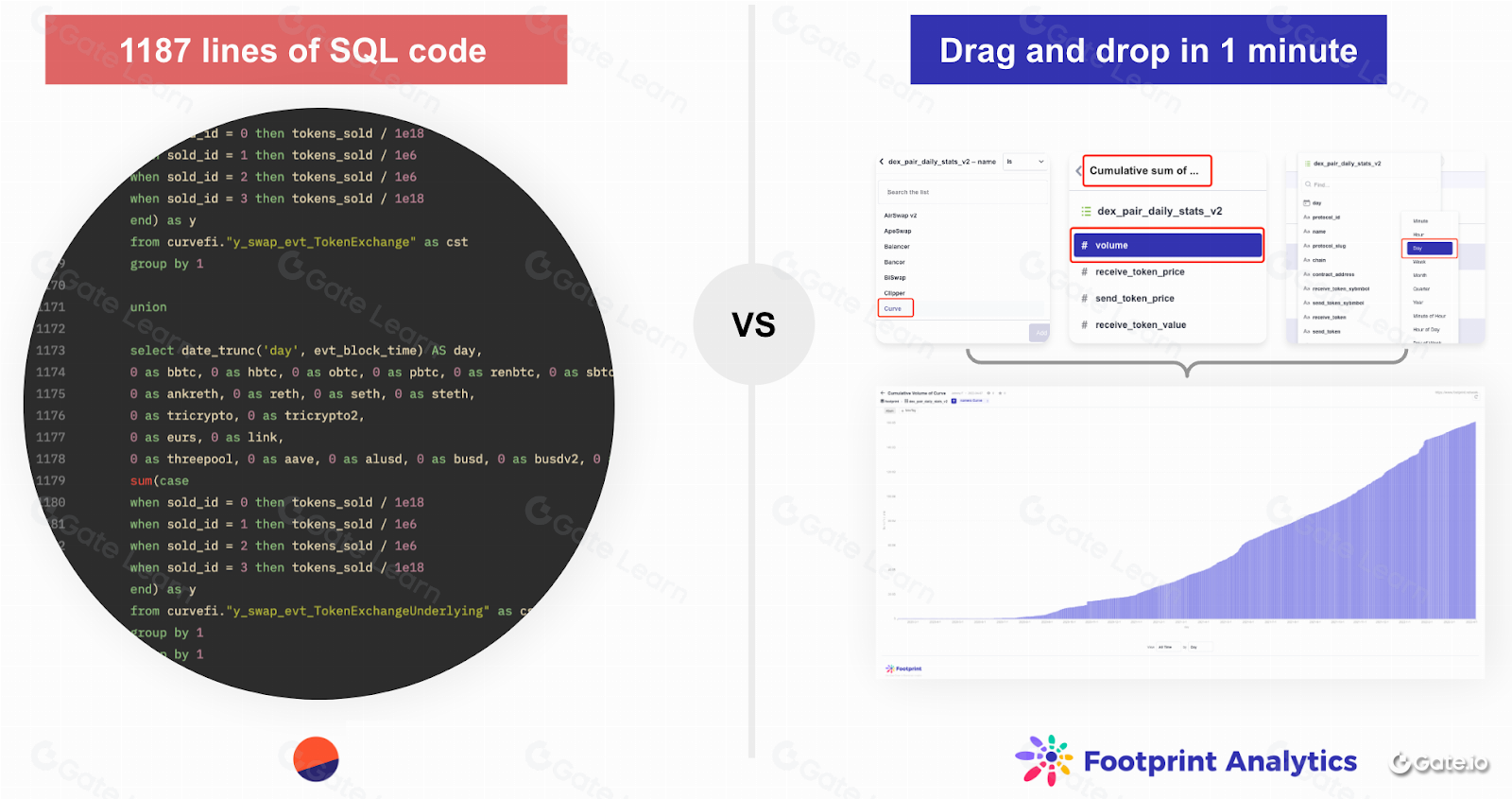
It’s not a stretch to let users add different metrics from different projects into a chart to compare them. Dune Analytics requires SQL to do this. Others, like Nansen, offer customizable charts on a much more limited scale. But what if you want to compare data from different chains? This is where things get tricky. At Footprint, we’ve developed a model that aggregates this raw data and indexes it to be meaningful.
The info about these millions of transactions is broken up by domain—our data engine determines whether it can be classified as GameFi, NFT, DEX, or other. We decode this data so analysts can search for the information they need, like block time, TVL, token price, etc., and immediately display that data on a chart.
Instead of strings of numbers and letters that are, to most, indecipherable, you have wallet addresses, chains, NFT collections, and other meaningful categories.

On the other hand, experienced analysts who want more flexibility can also work with raw data using SQL or Python.
Building a data engine that is the most comprehensive in the industry (we currently cover 22 chains) while retaining best-in-class performance was no easy feat of engineering.
The following article explains our data design in-depth.
The problem of cross-chain analytics
You can’t compare apples to oranges.
What would the peel thickness of a Golden Delicious be, or the number of seeds in the core of a Cara Cara orange? That makes no sense, obviously, but things start making sense when you compare sweetness, size, hardness, global consumption—things that can be quantified for both fruits in a logical way.
This logical categorization is like structured semantic data. No matter what the code for minting an NFT in Solana looks like, and no matter what it looks like in Ethereum, one needs to find a way to put all of this data into one category, called “Minting.”

Most major blockchain analytics solutions allow you to compare apples to oranges. However, at Footprint Analytics, we can compare apples to oranges to kiwis to pineapples and the list goes on.
As of December, we parse data from 22 different chains, more than any other platform. The Footprint Analytics database automatically picks up blocks, logs, traces, and transactions on the blockchain. It supplements this with community-contributed data and data from 3rd party APIs (e.g. token price data from Coingecko.) All this data is originally raw and unstructured. We structure it to fit into categories, e.g. borrowing, lending, yield farming, etc. This way, any data from the blockchain is easily accessible by anyone.
How Footprint Analytics balances flexibility and simplicity
Footprint web application is built on Metabase open source technology. Read more about Metabase. We use Metabase because it is open—the technology allows users to contribute to the code base, developing and improving it over time.
For example, in the latest update of Metabase the models are introduced. This functionality is allowing users to curate data from another table or tables from the same database to anticipate the kinds of questions people will ask of the data.
Analysts can create charts on the Footprint Analytics platform with a convenient drag-and-drop query builder. This capability significantly lowers the barrier to entry, allowing any user without technical knowledge to use the product and extract business value.

It is important to note that, architecturally, Metabase is an abstraction over SQL code; that is, any request made by drag and drop can be represented as SQL. Thus, users who want to build more complex queries or who prefer to work with data using code have the opportunity to use SQL straight away.
Many alternative analytics solutions allow the user to analyze different networks according to various levels of requirements. However, for the most part, alternative solutions tend to go to extremes, implementing either a very flexible product that requires knowledge of query languages or even programming languages a very simple interface with prepared scripts and, accordingly, low flexibility.
Coverage
We have one of the widest coverages in the entire market. We describe the current coverage in detail, referring to the organization of the data (levels, domains), within the following section.
How does Footprint Analytics parse so much data?
Our core competitive advantage is our Footprint Analytics Platform, powered by the Footprint Machine Learning Platform.
The “Footprint Analytics platform” can refer to the website users see when they go to footprint.network. However, when we talk about the Footprint Analytics Platform, we’re also referring to the engine that does the heavy lifting under the hood.
Levels
It turns the Bronze Data into Silver, then Gold using some technical means of data ETL, such as Python and SQL. In the future, we plan to make the ETL code, including the code from Bronze to Silver parsing, open source.
We also enable any organization to tap into this trove of structured data with our blockchain data API.
Get the world’s richest blockchain data with our Footprint Data API
The UI is not the only interface that could be used to access the data. All currently supported interfaces are listed here : Interfaces
Before Footprint Analytics, blockchain analysis was limited to incomplete and unstructured data. Furthermore, organizations that used even the leading solutions faced delays in access, performance limitations and costly API aggregation.
Thanks to our platform that parses on-chain data from 23 chains into the Silver and Gold tiers mentioned above, any organization can tap into most of the world’s GameFi, NFT and DeFi data, all with one unified API. Both REST API and SQL API are supported at Footprint Analytics.
What kind of apps can you build with this data? Here are just a few examples:
- Track the best and worst gamer retention rates across all GameFi titles
- Trigger alerts when whale wallets bring their money in or out of chains or protocols of interest
- Compare cross-chain fluctuations in TVL with commodity prices
- Create custom displays for NFT collections from multiple networks
- Discover the latest hot collections and access in-depth analytics for 15K+ projects
- Follow and track whales’ fund flows to identify investment opportunities and potential risks
With Footprint, anybody can get one step closer to blockchain analytics, whether you’re an investor, analyst, retail trader, developer, or just exploring your favorite crypto project.
Lesson 1:On-chain Data in Web3
Lesson 2:How Does Footprint Analytics Make Sense?
Lesson 3:Iceberg + Spark + Trino: a Modern Open Source Data Stack For Blockchain
Lesson 4:How Footprint Analytics Helps Blockchain Researchers?
Lesson 5:How Do the Three Major Crypto Analytics Platforms Differ
Related courses

The Beginner's Guide to Blockchain-based Airdrops
The Beginner's Guide to Blockchain-based Airdrops

Crypto Mining Equipment
Crypto Mining Equipment

Crypto Mining
Crypto Mining

Blockchain Fundamentals
Blockchain Fundamentals

Supply Chain Management and Blockchain Applications
Supply Chain Management and Blockchain Applications

Crypto Tax
Crypto Tax
How Does Footprint Analytics Make Sense?
Footprint Analytics is a blockchain analytics tool that allows users to gather, structure, and visualize data from multiple different blockchain chains. In this module, you'll understand what's the advantage of selecting Footprint as your data analystics tool.
The open data of the blockchain isn’t worth anything unless people can access and understand it. Those new to crypto tend to look at token prices exclusively, which is easy enough. However, as people gain experience in blockchain, they realize that to truly understand the market, one needs to pool-level data for DeFi, retention data for GameFi, and more—think about TVL, wallet info and deposits/withdrawals.
What if you want to investigate whale movements between different projects? Or get the full picture of a PR crisis’ impact on a protocol? How does one get this kind of data, and how can they create custom solutions to answer highly-specific questions?
Getting this raw, unfiltered data from a single chain is not that technically difficult. That’s why there are dozens of services out there in the blockchain analytics space. The process essentially entails structuring the data—standardizing the millions of lines of data being fed into a database, especially with such heterogeneous technical implementation of blockchains. With some crafty UX programming, it is converted into a visually comprehensible form.
It’s not a stretch to let users add different metrics from different projects into a chart to compare them. Dune Analytics requires SQL to do this. Others, like Nansen, offer customizable charts on a much more limited scale. But what if you want to compare data from different chains? This is where things get tricky. At Footprint, we’ve developed a model that aggregates this raw data and indexes it to be meaningful.
The info about these millions of transactions is broken up by domain—our data engine determines whether it can be classified as GameFi, NFT, DEX, or other. We decode this data so analysts can search for the information they need, like block time, TVL, token price, etc., and immediately display that data on a chart.
Instead of strings of numbers and letters that are, to most, indecipherable, you have wallet addresses, chains, NFT collections, and other meaningful categories.
On the other hand, experienced analysts who want more flexibility can also work with raw data using SQL or Python.
Building a data engine that is the most comprehensive in the industry (we currently cover 22 chains) while retaining best-in-class performance was no easy feat of engineering.
The following article explains our data design in-depth.
The problem of cross-chain analytics
You can’t compare apples to oranges.
What would the peel thickness of a Golden Delicious be, or the number of seeds in the core of a Cara Cara orange? That makes no sense, obviously, but things start making sense when you compare sweetness, size, hardness, global consumption—things that can be quantified for both fruits in a logical way.
This logical categorization is like structured semantic data. No matter what the code for minting an NFT in Solana looks like, and no matter what it looks like in Ethereum, one needs to find a way to put all of this data into one category, called “Minting.”
Most major blockchain analytics solutions allow you to compare apples to oranges. However, at Footprint Analytics, we can compare apples to oranges to kiwis to pineapples and the list goes on.
As of December, we parse data from 22 different chains, more than any other platform. The Footprint Analytics database automatically picks up blocks, logs, traces, and transactions on the blockchain. It supplements this with community-contributed data and data from 3rd party APIs (e.g. token price data from Coingecko.) All this data is originally raw and unstructured. We structure it to fit into categories, e.g. borrowing, lending, yield farming, etc. This way, any data from the blockchain is easily accessible by anyone.
How Footprint Analytics balances flexibility and simplicity
Footprint web application is built on Metabase open source technology. Read more about Metabase. We use Metabase because it is open—the technology allows users to contribute to the code base, developing and improving it over time.
For example, in the latest update of Metabase the models are introduced. This functionality is allowing users to curate data from another table or tables from the same database to anticipate the kinds of questions people will ask of the data.
Analysts can create charts on the Footprint Analytics platform with a convenient drag-and-drop query builder. This capability significantly lowers the barrier to entry, allowing any user without technical knowledge to use the product and extract business value.
It is important to note that, architecturally, Metabase is an abstraction over SQL code; that is, any request made by drag and drop can be represented as SQL. Thus, users who want to build more complex queries or who prefer to work with data using code have the opportunity to use SQL straight away.
Many alternative analytics solutions allow the user to analyze different networks according to various levels of requirements. However, for the most part, alternative solutions tend to go to extremes, implementing either a very flexible product that requires knowledge of query languages or even programming languages a very simple interface with prepared scripts and, accordingly, low flexibility.
Coverage
We have one of the widest coverages in the entire market. We describe the current coverage in detail, referring to the organization of the data (levels, domains), within the following section.
How does Footprint Analytics parse so much data?
Our core competitive advantage is our Footprint Analytics Platform, powered by the Footprint Machine Learning Platform.
The “Footprint Analytics platform” can refer to the website users see when they go to footprint.network. However, when we talk about the Footprint Analytics Platform, we’re also referring to the engine that does the heavy lifting under the hood.
Levels
It turns the Bronze Data into Silver, then Gold using some technical means of data ETL, such as Python and SQL. In the future, we plan to make the ETL code, including the code from Bronze to Silver parsing, open source.
We also enable any organization to tap into this trove of structured data with our blockchain data API.
Get the world’s richest blockchain data with our Footprint Data API
The UI is not the only interface that could be used to access the data. All currently supported interfaces are listed here : Interfaces
Before Footprint Analytics, blockchain analysis was limited to incomplete and unstructured data. Furthermore, organizations that used even the leading solutions faced delays in access, performance limitations and costly API aggregation.
Thanks to our platform that parses on-chain data from 23 chains into the Silver and Gold tiers mentioned above, any organization can tap into most of the world’s GameFi, NFT and DeFi data, all with one unified API. Both REST API and SQL API are supported at Footprint Analytics.
What kind of apps can you build with this data? Here are just a few examples:
- Track the best and worst gamer retention rates across all GameFi titles
- Trigger alerts when whale wallets bring their money in or out of chains or protocols of interest
- Compare cross-chain fluctuations in TVL with commodity prices
- Create custom displays for NFT collections from multiple networks
- Discover the latest hot collections and access in-depth analytics for 15K+ projects
- Follow and track whales’ fund flows to identify investment opportunities and potential risks
With Footprint, anybody can get one step closer to blockchain analytics, whether you’re an investor, analyst, retail trader, developer, or just exploring your favorite crypto project.
Related courses
The Beginner's Guide to Blockchain-based Airdrops
The Beginner's Guide to Blockchain-based Airdrops
Crypto Mining Equipment
Crypto Mining Equipment
Crypto Mining
Crypto Mining
Blockchain Fundamentals
Blockchain Fundamentals
Supply Chain Management and Blockchain Applications
Supply Chain Management and Blockchain Applications